How many people, in which countries, can use the left-right scale?
polling
code
left-right
Author
Chris Hanretty
Published
January 16, 2025
Abstract
You shouldn’t investigate mass-elite linkages on the left-right scale in Brazil. Or South Africa. Or Hong Kong. Or indeed quite a few country years.
The left-right scale is one of the most commonly used scales in political science. It’s one of the few scales that is so well known that we allow respondents to position themselves on a numeric scale, rather than asking them a series of more concrete questions and inferring a position.
The left-right scale is unlike happiness or pain scales because it’s possible that some people don’t know how to use it. We would regard a survey respondent as unusual—and possibly a philosopher —if, in response to a question about life satisfaction, they said that they didn’t know what life satisfaction was. We would regard someone as psychotic if they gave a similar response when asked about pain.
For the left-right scale, there are going to be some people who (say they) don’t know what left and right mean. They may:
say explicitly that they don’t know what left and right mean, or
be unable to give any response to a question asking them to place themselves on a left-right scale, or
give placements of objects on this scale that are so odd as to call into question their ability successfully to use the scale
We can work out the proportion of people in these categories using data from the Comparative Study of Electoral Systems (CSES). For most country-years,1 the CSES asks respondents to place themselves on a 0-10 left-right scale, and asks them to place parties. For most country-years, survey teams recorded when the respondent volunteered that they hadn’t heard of the left-right scale, or when the respondent volunteered that they couldn’t place themselves.
We can calculate some of these proportions using the CSES integrated data.
Across almost all election studies conducted by CSES:
the average proportion of respondents who volunteered that they hadn’t heard of the left-right scale was 2.
the average proportion of respondents who said that they couldn’t place themselves on the left-right scale was 11
The average sum of these two proportions was 14, and the total proportion of responses that were missing, for whatever reason including refusal, was 20.
These proportions set a lower bound on the proportion of people who can use the left-right scale. Some people will give a response to questions about the left-right scale, but use it in ways that suggest they don’t understand it.
At the national level, we can calculate the association between the average placement given to each party, and the placement given by CSES project teams – who presumably do understand the left-right dimension.
(Although in principle it would be possible to calculate the correlation at individual level, awkward issues arise where respondents evaluate different numbers of parties).
Across all studies, the average correlation is fairly healthy, at 0.78. Indeed, given that questions about party placements have made it into a cross-national survey programme, we would expect the question to give roughly sensible answers. But that doesn’t mean it’s sensible in all circumstances.
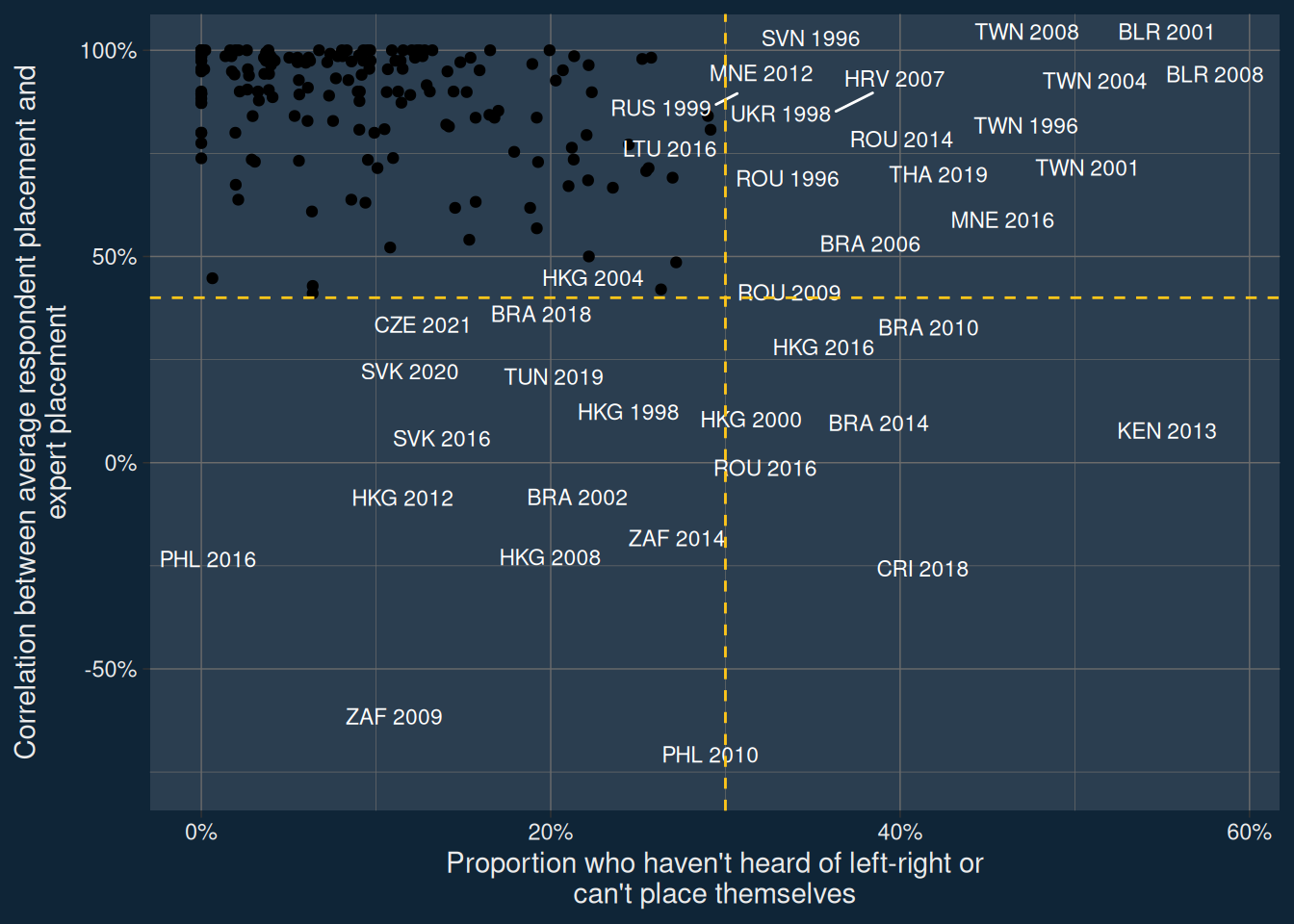
Figure 1: A scatter-plot showing the proportion who either haven’t heard of the left-right scale or who can’t place themselves on it (horizontal axis) against the correlation between average respondent party placements and expert party placements (vertical axis)
In Figure 1 I’ve plotted two measures of “how much left-right makes sense”: the proportion who can’t place themselves or haven’t heard of left and right, and the correlation between citizen and expert placements. I’ve divided the plot into four quadrants, choosing a cut-off of 30% on the horizontal axis, and \(r = 0.4\) on the vertical axis.
In the bottom right quadrant, we’ve got country-years where lots of people said they didn’t grok left-right, and where the placements proved that. Costa Rica in 2018 is perhaps the most extreme example, but there’s a pretty good showing from some Brazilian elections here.
In the top right quadrant, we’ve got country-years where lots of people said they didn’t grok left-right, but where those people who did use placements did so accurately. Here we have countries which have other major dimensions of competition (like Taiwan) or countries which in my view should never have been surveyed (like Belarus).
In the bottom left quadrant, we’ve got countries where people talked a good game, but where their performance left a lot to be desired. South Africa is a good case in point – here, the correlation between expert placements and citizen placements is pretty strong, but exactly the wrong way round, with citizens placing Julius Malema’s Economic Freedom Fighters on the right, which doesn’t make a lick of sense.
Finally, in the top left quadrant we’ve got the bulk of studies ( 176 / 219), where few people volunteer that they haven’t heard of left-right, and where people on average seem to be able to use it correctly.
This division into quadrants is partly arbitrary, and based on knowledge of a small number of cases. First, I believe that left and right make sense in UK politics. As a result, the threshold for the proportion of people who either haven’t heard of—or can’t place themselves using—the left right scale is set based on the proportion in the UK in 2005, where a rather surprising 25.5% of respondents said they couldn’t place themselves. Second, I believe that left and right don’t make much sense in Hong Kong politics, where the pro/anti-Beijing cleavage was far more important at the time these surveys were conducted. As a result, the threshold for the correlation between citizen and expert placements is set at above 0.4, the correlation in Hong Kong is 2004, and the maximum correlation amongst the six Hong Kong studies.
This means that if we want to study citizen-elite linkages on the left-right spectrum, we’re presently limited to the analysis of around 176 country-years, and our knowledge grows by around seven country-years per year. Big data might have arrived in other domains, but not here.
Footnotes
The question wasn’t asked in Japan in 1996 and 2004; in Taiwan in 2012, 2016, and 2020, or in Thailand in 2001 or 2011.↩︎