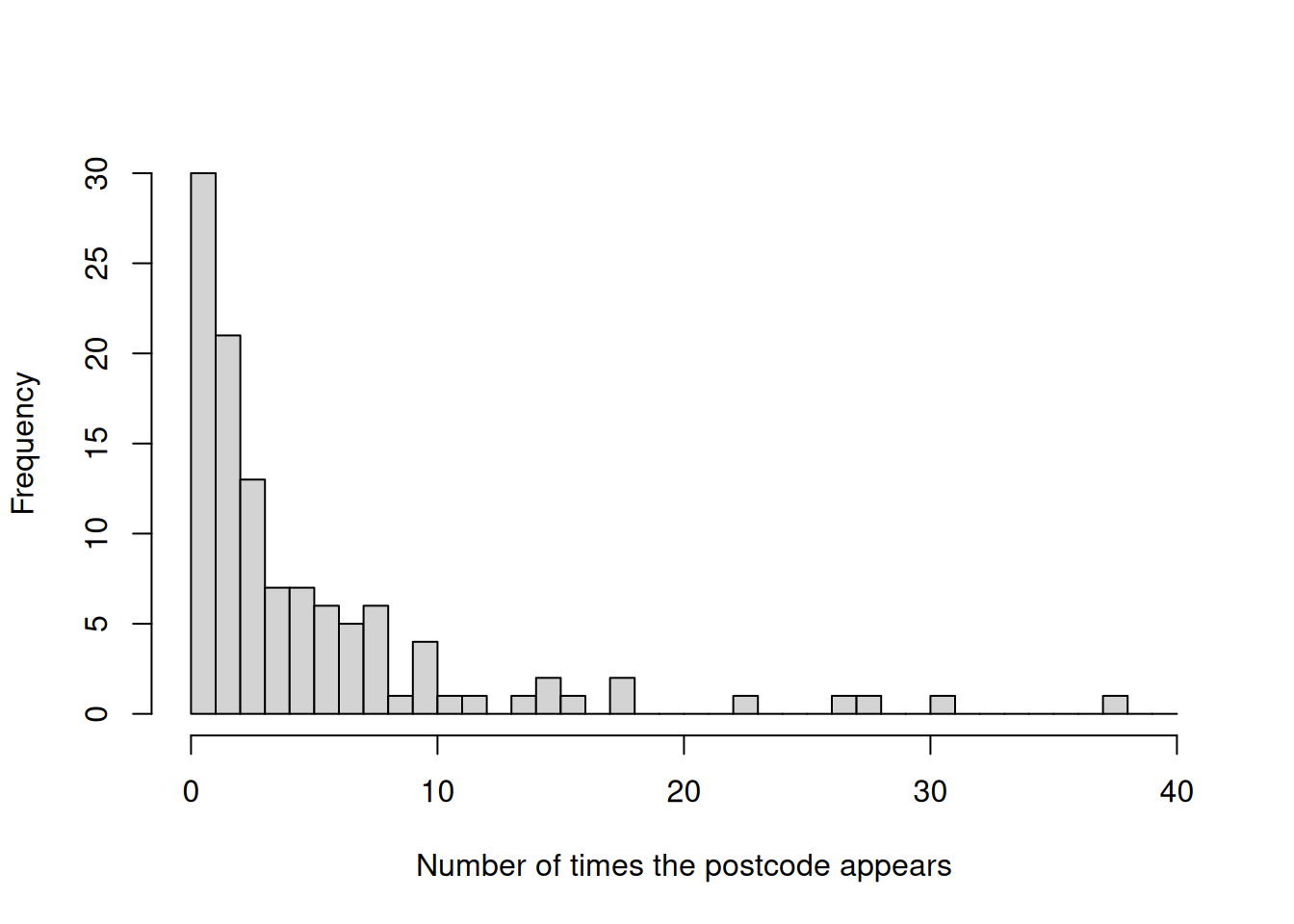
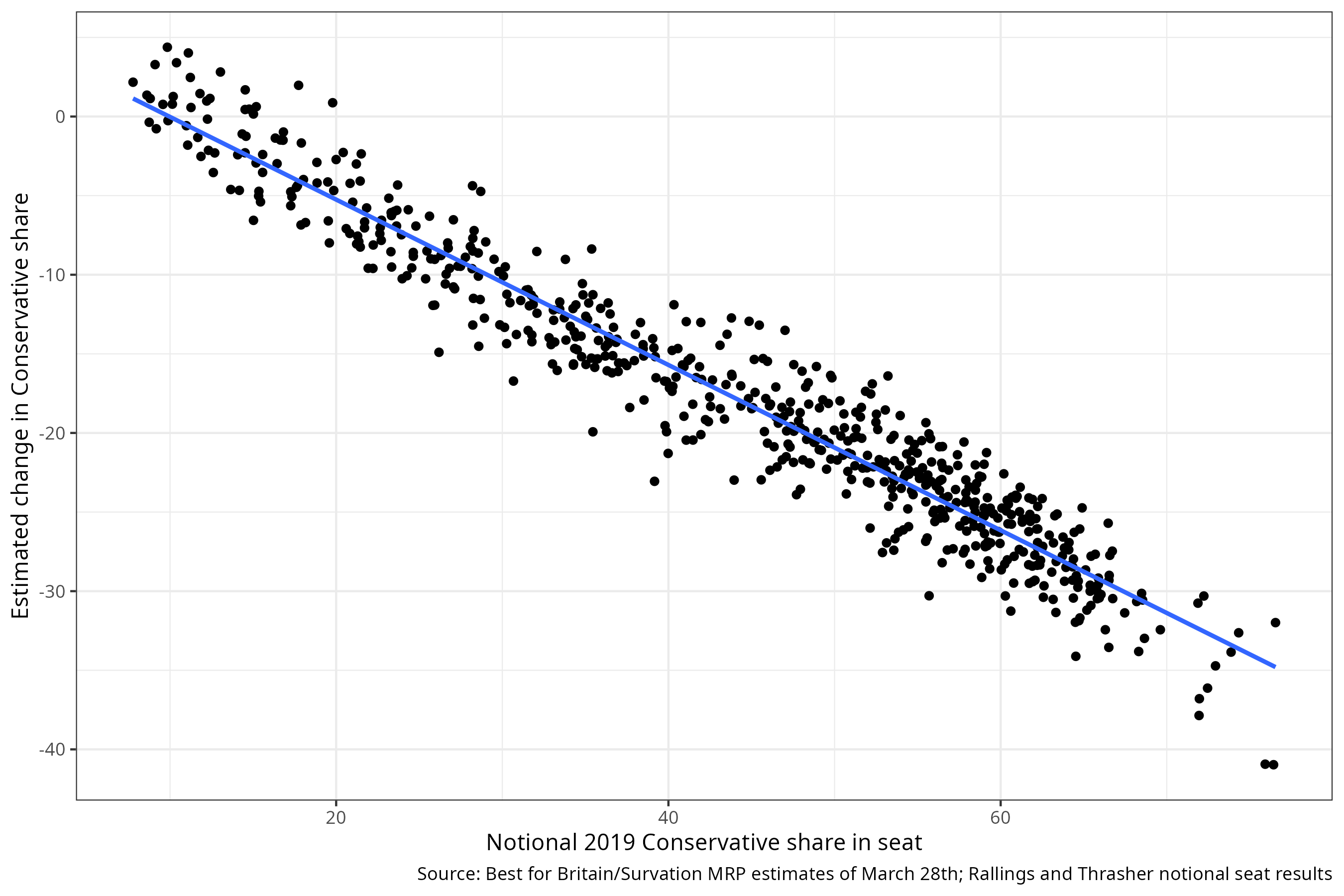
Over six thousand Leave voters have died in Makerfield since 2016; this is more than the number of Remain voters who have died since then (2003)
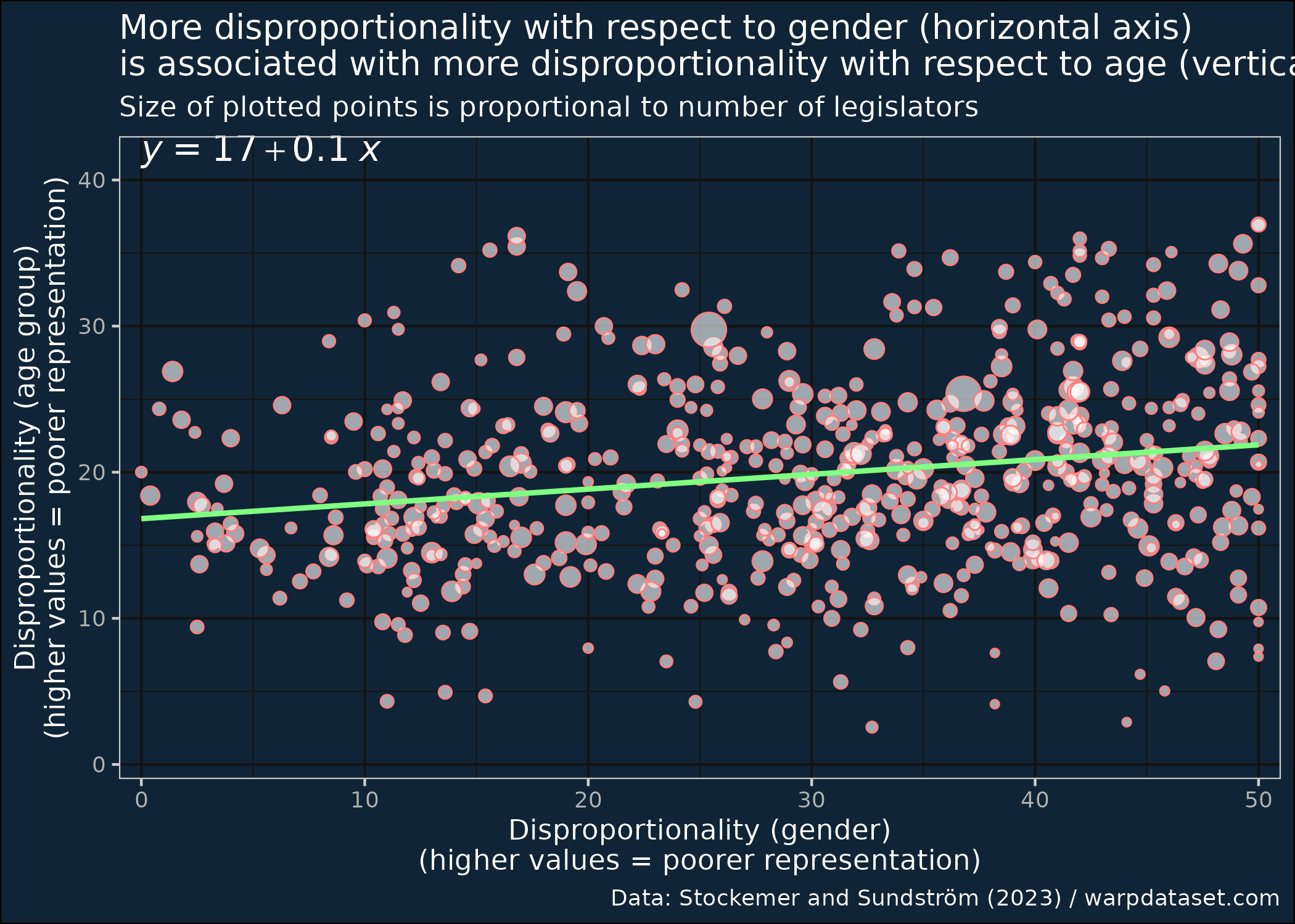
I introduce an extension of the Sainte-Laguë index which allows for the calculation of disproportionality in mixed member systems. The index is based on the joint distribution of votes cast across both tiers, and relies on differences in advantage ratios between types of voters, defined by the parties they supported in each tier.
tl:dr version: David Klemperer’s proposal for the UK to adopt a two-round system is wrong about the benefits of proportional representation and misunderstands French politics.
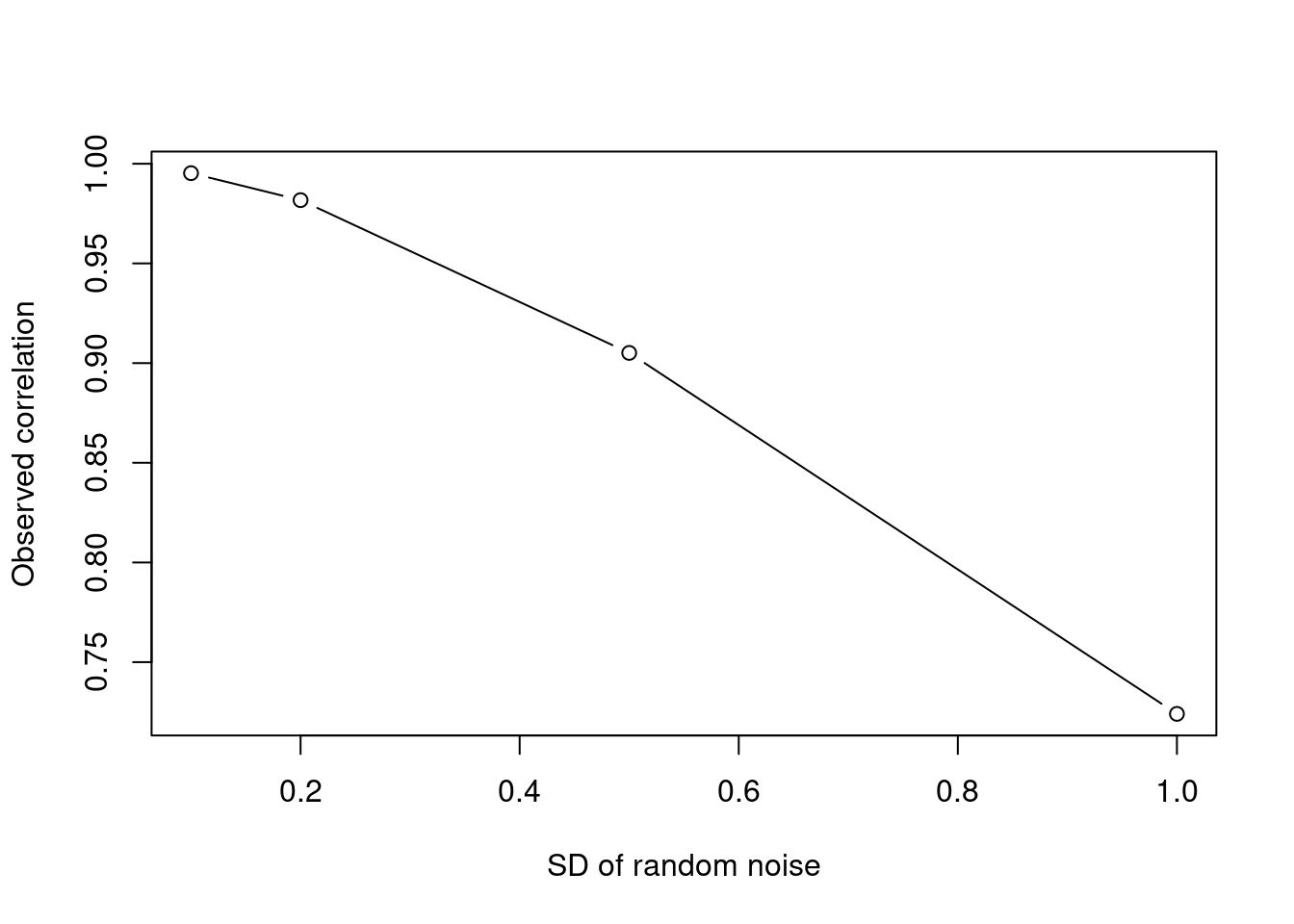
I compare different ways to code up the same simulation, and get a 30x speed-up
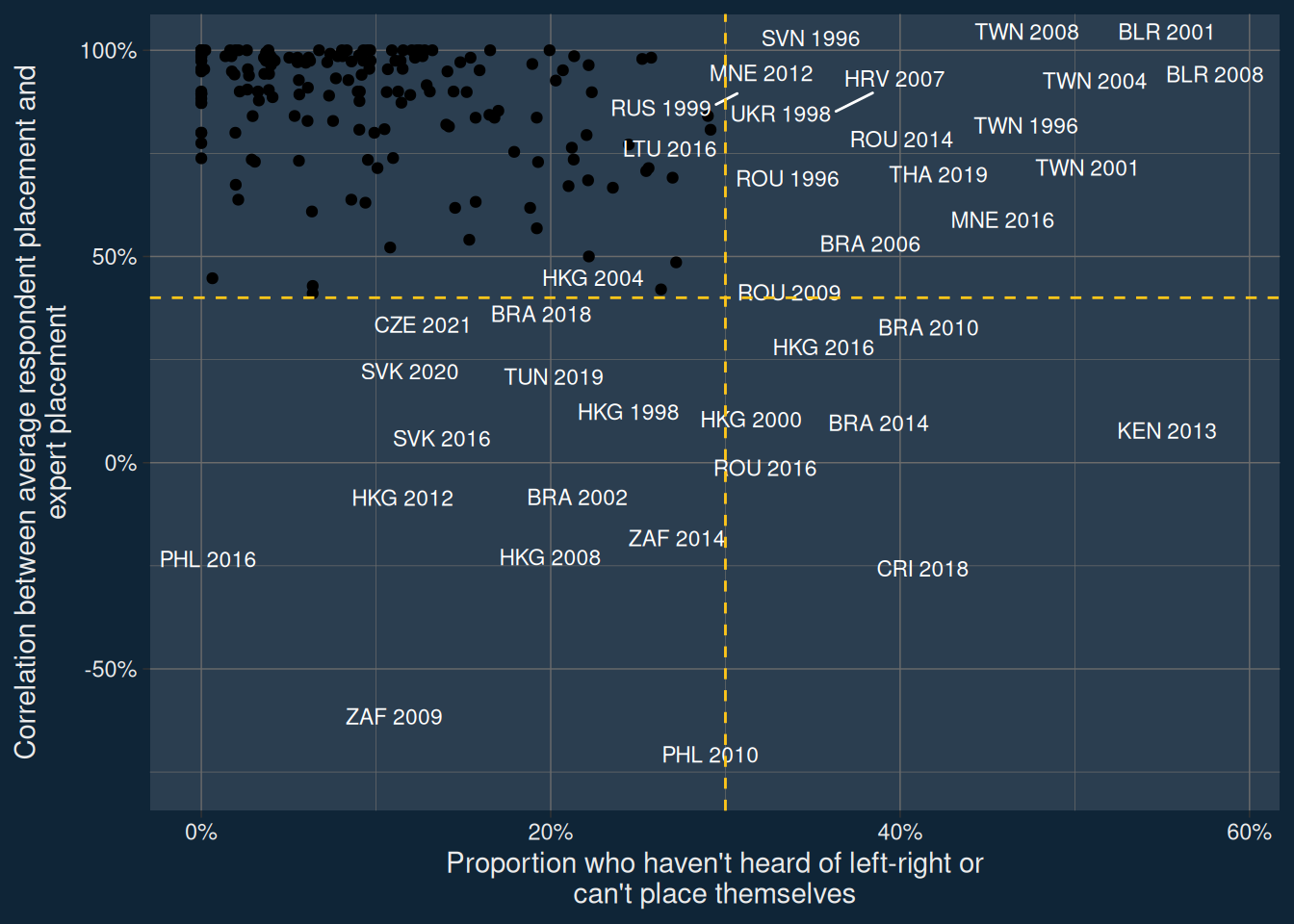
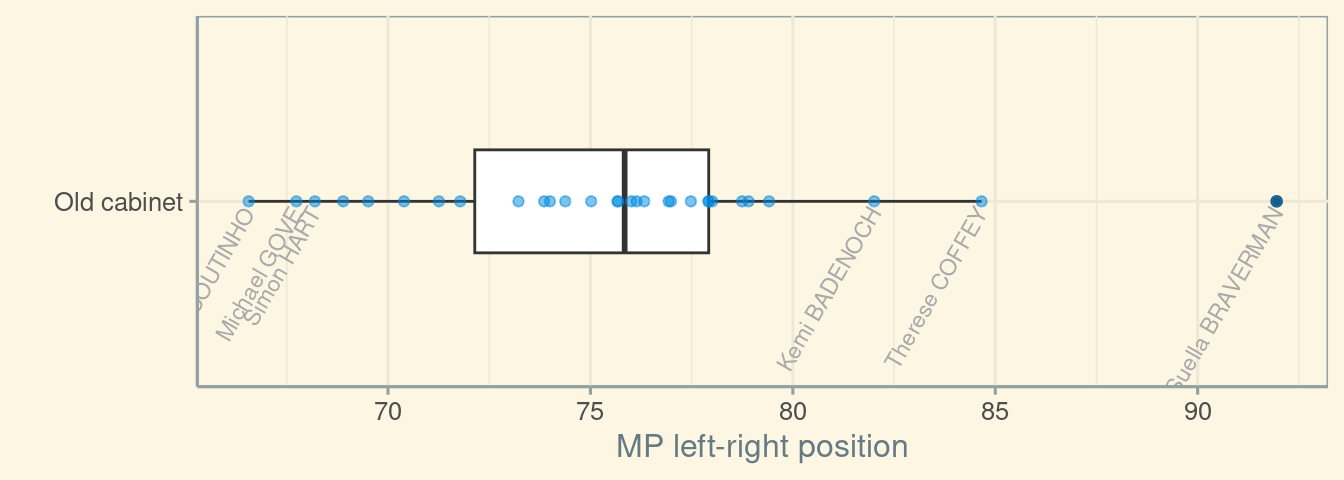
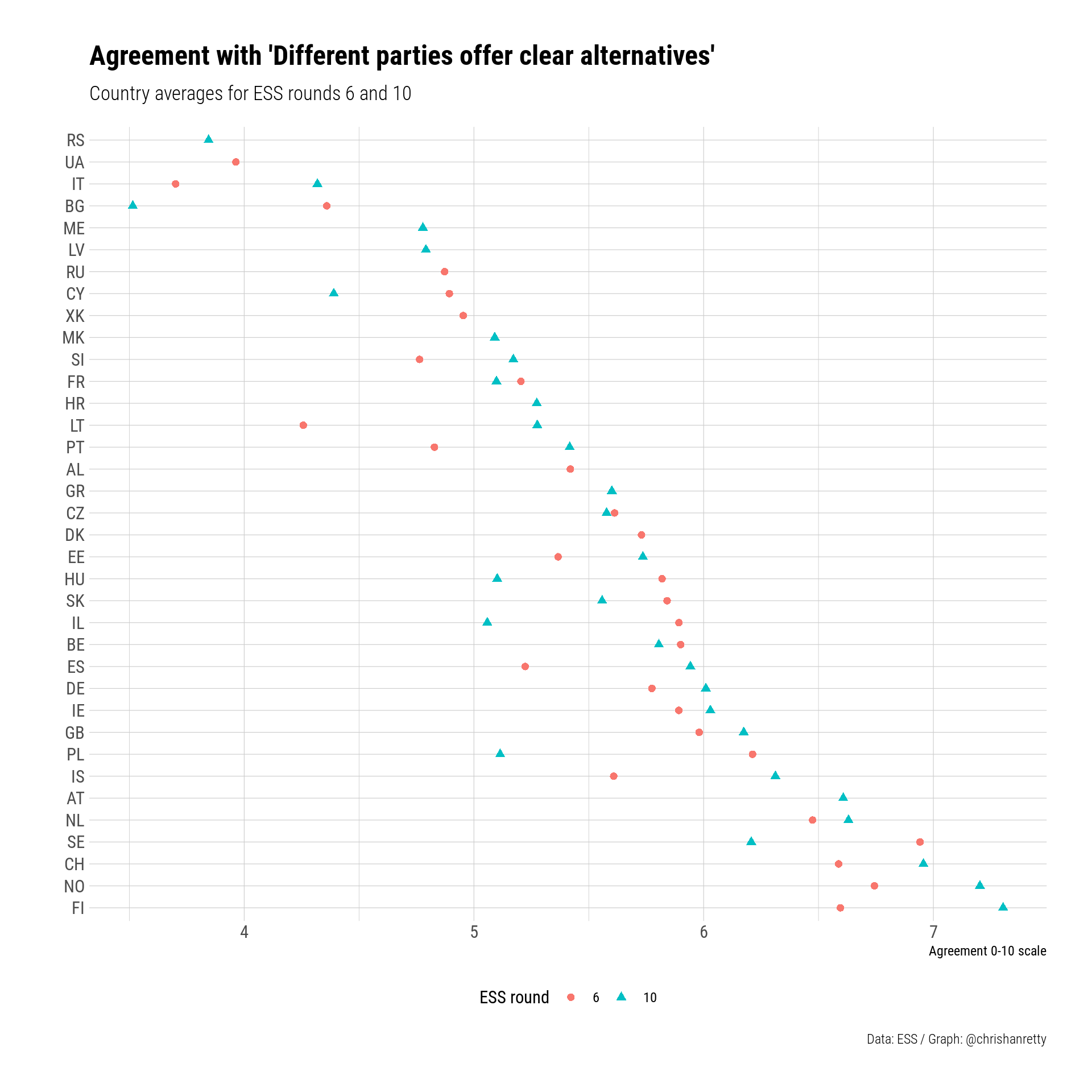
You shouldn’t investigate mass-elite linkages on the left-right scale in Brazil. Or South Africa. Or Hong Kong. Or indeed quite a few country years.
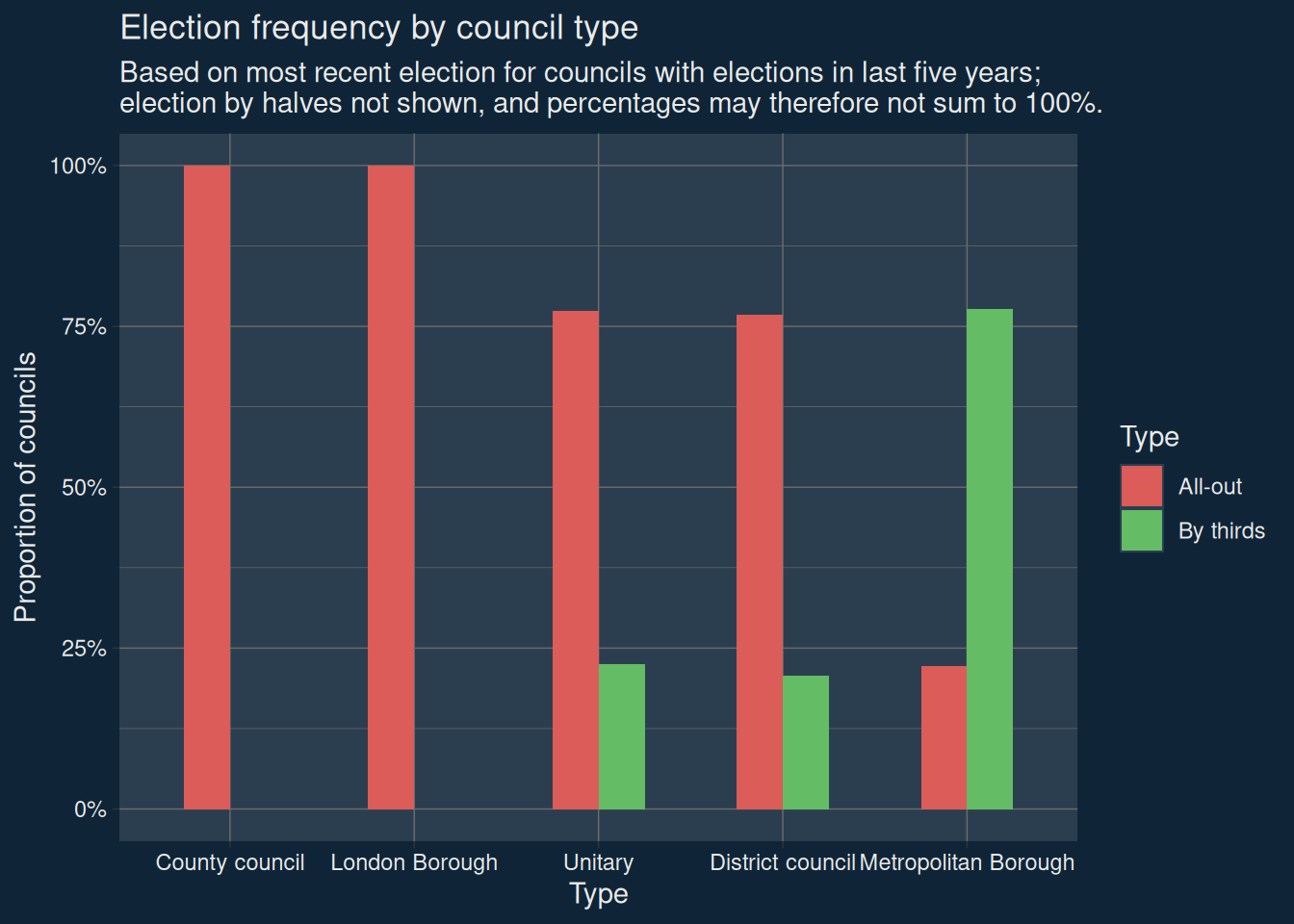
Unitarisation would probably mean moving away from election by thirds – and this is a good thing, because turnout in all-out elections is higher by around a percentage point.
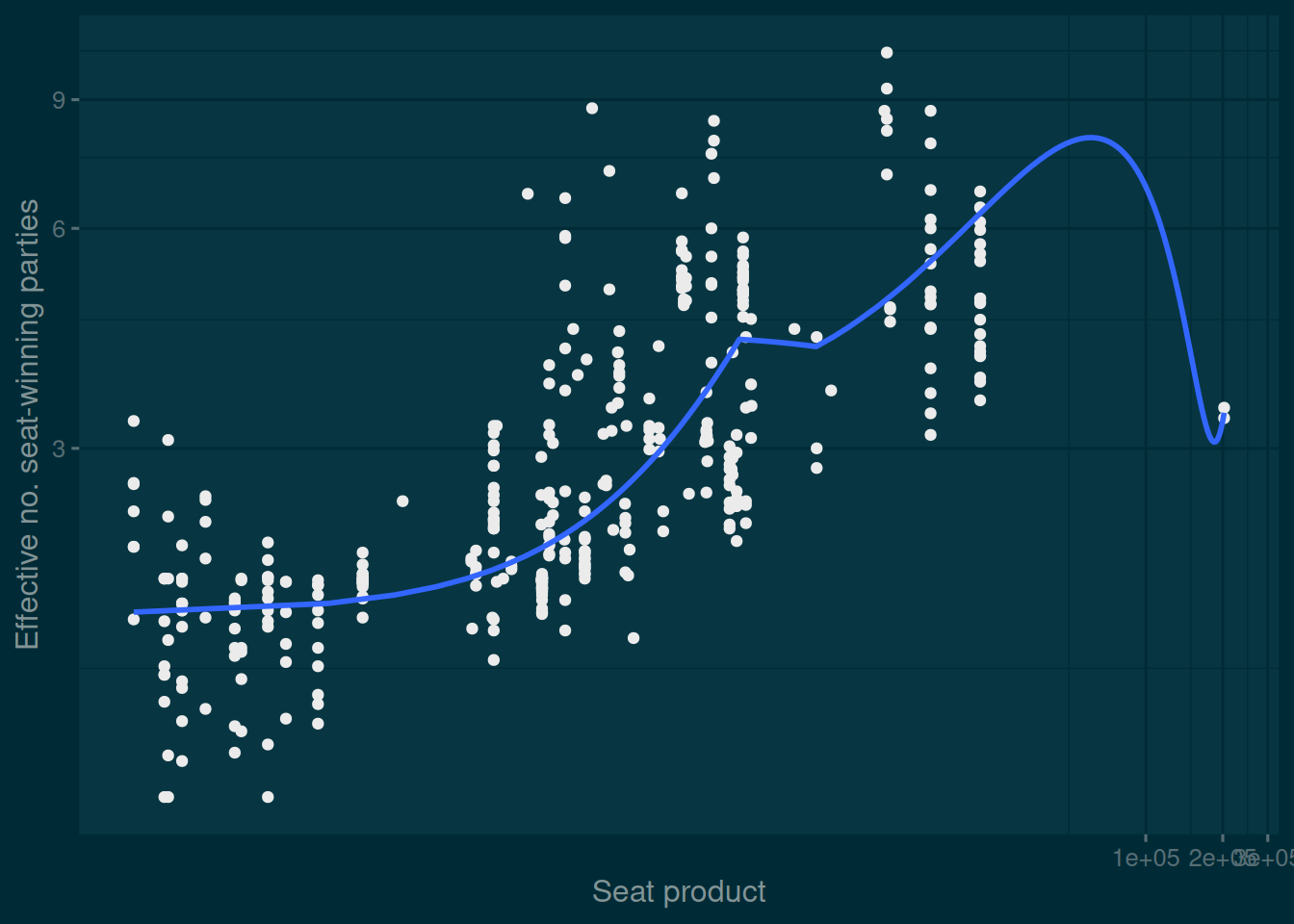
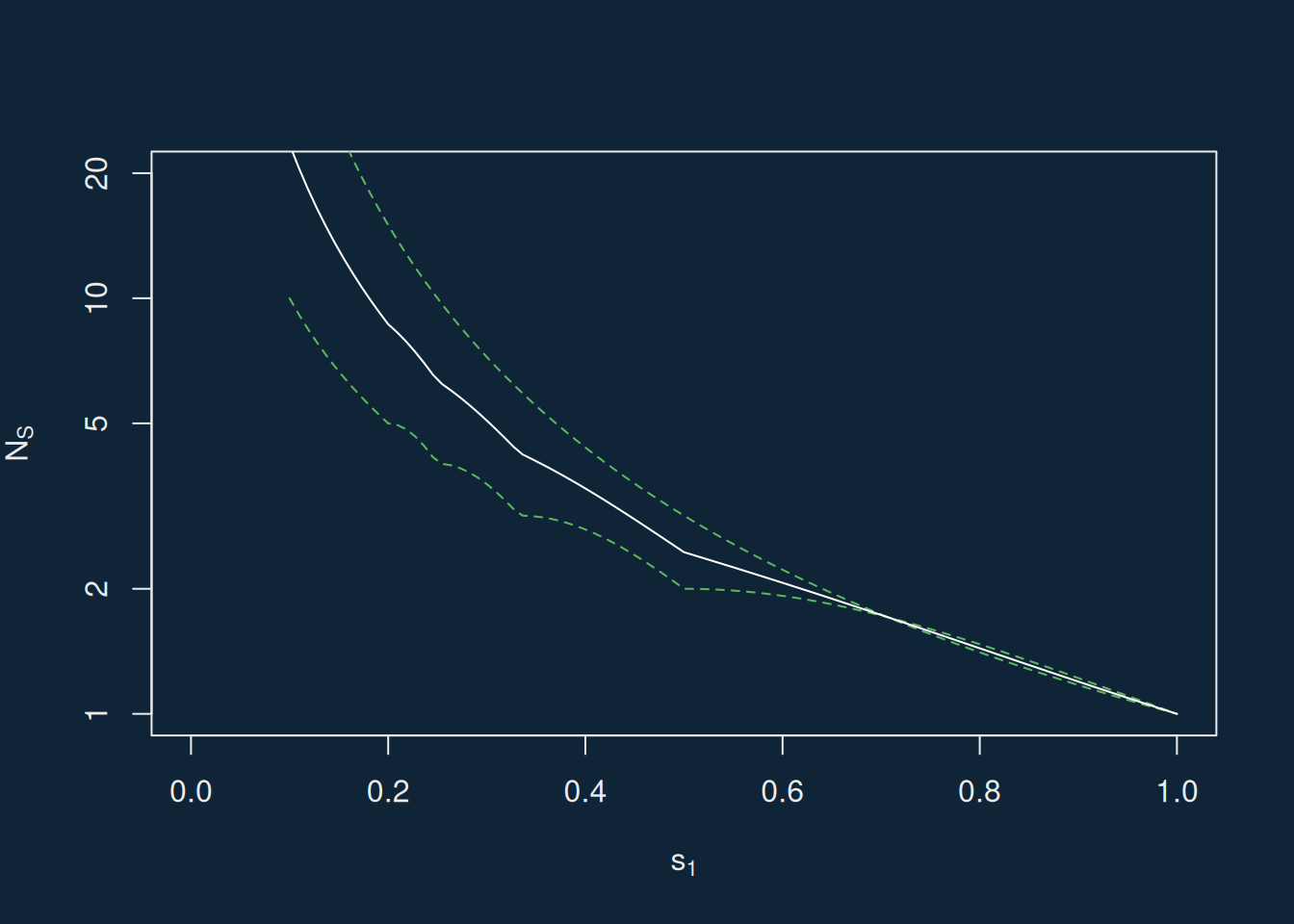
The average number of divisors of the size of legislative chambers is greater than the average number of divisors of simulated data which replicates the mean and dispersion of those sizes. It’s therefore easier to split them up into equally-sized districts.